Smart IVR
This's a software kit enables to build fully autonomous, privacy intelligent IVR services based on Freeswitch.
The kit consists of various modules / libraries, usually supplied as a boxed-solution (a ready-made server or can be installed on your virtual machine), there are some modules that available separately.
What's this for?
- Relieve (or even completely replace) first-line personnel
solving typical user problems in dialogue mode, fully automatically
- Receiving complaints/applications/etc in a voice form
transcription (classification) and subsequent transfer to some your ticket system
- Working as an information agent
making calls with reminder/confirmations and so on
- Working as a secretary
receiving, filtering, forwarding calls and so on
- Cold calls
surveys and so on
So, this is another GPT AI agent?
No. This thing going by another way, in contrast of LLM (where models consist all things as possible), it uses lightweight NLP (v1) and models trained specifically for your tasks, with the logic in javascript,
which allows to have fully autonomous systems (running on your side) with maximum performance on a quite cheap equipment.
Local TTS/STT services ensure the safety of users personal data and biometrics.
For example: Core2 Quad with 4G memory will be enough to handle 2-3 simultaneous dialogues.
Of course, if your security policy allows to use external GPT services (like ChatGPT/DeepSeek/...) or you have the resources to run them locally, then they can be integrated into the system without any problems.
Unfortunately, LLM is still a fairly resource-intensive solution and not everyone can afford to have it in production, as well as using public GPT services, in such systems it might lead to the following troubles:
- Corporate data leak
Initially, LLM models don't know anything about your business, therefore, for normal operation, you have to retrain the models on your data (which may contain some confidential information), onsequently, all this becomes available to the third parties (service owners and maybe someone else)
- Users personal data leak
As well as the item above, here, we get the same but with user data, during the conversation with the system some of the user personal information may be required (contract/ID number, PIN code and so on) and all this also becomes available to the third parties
- Biometrics leak (voice features)
This possible problem might be more dangerous than the whole previous ones put together.
So, when the sevice uses any external Speech-to-Text service, nothing can prevents it from collecting and extracting voice fingerprints from audio fragments (unless special means are used to avoid this).
Then this can be used to identify users by voice (without their knowledge) or in voice synthesizers to create fakes... - Resource intensity and expensive of LLM solutions (a review article on example of OpenAI)
As it mentioned before, LLM is quite expensive and resource-intensive solution, even if it has a low tokent price for you, the final request on the provider's hardware costs several times more (and it's only a matter of time when the token price suddenly changed for you).
The responsiveness of the system (delay in generating a response) also plays an important role, on basic tariffs you might easily get a delay around 20+ seconds, which brings discomfort to dialogues and irritation to users.
What languages are supported?
For asrd/ttsd the languages list is quite large, because they use opensouce models. (see the components description list)
NLP supported the following languages: russian, english (can be expanded if necessary)
Where I can test it?
Here's an online demo with several scenarios.
What's the price?
The final price is calculated after collecting and discussing all requirements.
Contact with me and will discuss it.
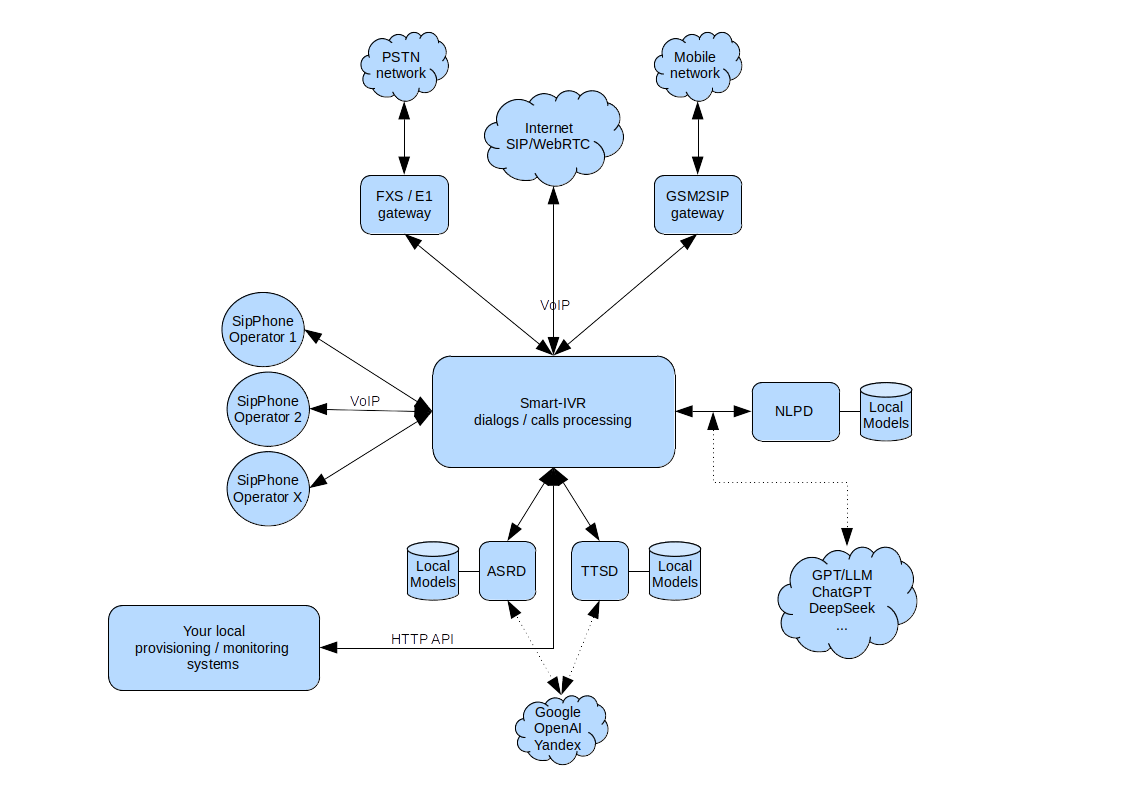
The kit components:
- asrd
High-performance speech-to-text service (pure с)
Capabilities: offline-transcription (local models, retraining), multilingual, voice features extraction (ivectors).
Languages: english, german, french, russian, full list
API: JSON-RPC, plain HTTP GET/POST - ttsd
High-performance text-to-speech service (pure с, opensouce version)
Capabilities: offline-synthesis (local models, retraining), multilingual, formats (MP3, WAV, L16).
Languages: english, german, french, russian, full list
API: JSON-RPC, plain HTTP GET/POST - nlpd (v1)
High-performance language processing service (java)
Capabilities: working with small datatset, fast retraining, multilingual mode.
Languages: english, russian (basic features: names, digits, phone numbers, locations*)
API: WebUI + JSON-RPC - sivr-manager
WebUI for managing the components (java + javascript)
- freeswitch + modules
Class 5 softswith + sivr special modules
The advantages:
- costs reduction (on personnel, equipment, external services) [* may possible]
- capability of working completely offline
- working on quite cheap equipment
- flexible adjustment to various tasks
- multilingual support
Components integration scheme