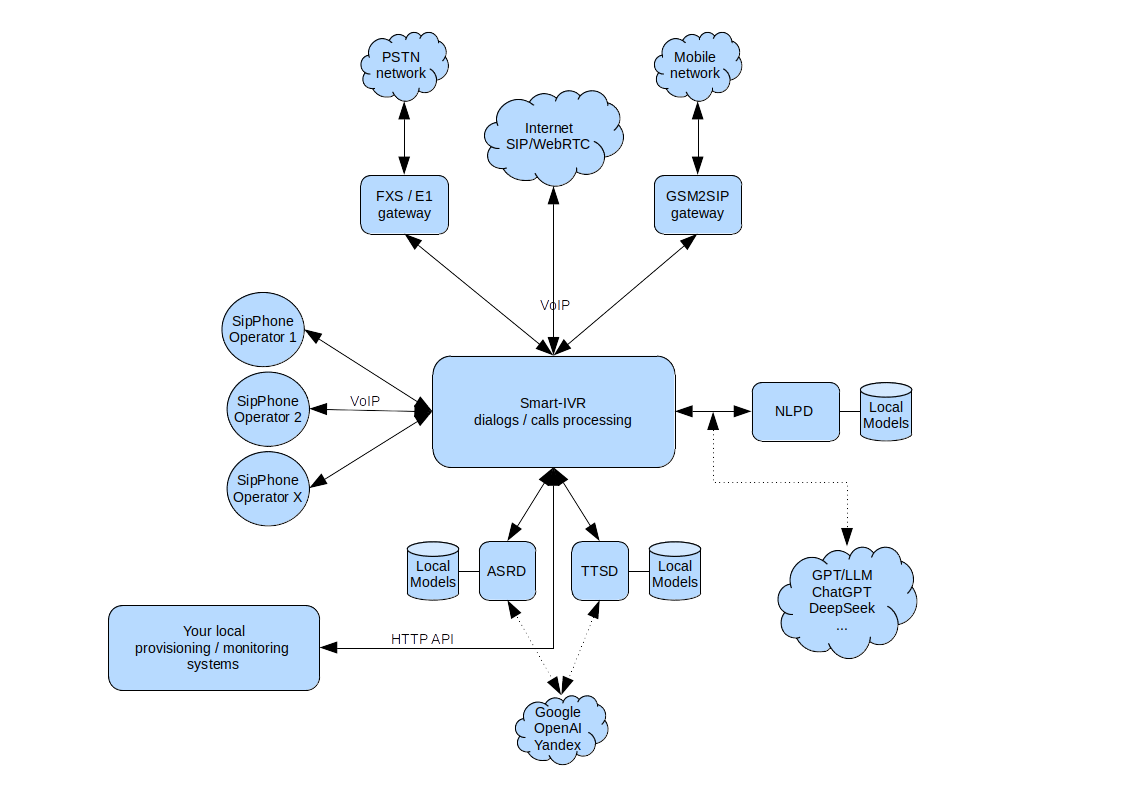
Smart IVR
Это комплект ПО, позволяющий создавать конфиденциальные, полностью автономные, интеллектуальные IVR системы на базе Freeswitch.
Комплект состоит из различных модулей/библиотек, обычно поставляется как коробочное решение (в виде готового сервера или c установкой на вашу вирт.машину), некоторые модули доступны по отдельности.
Для чего это?
- Для разгрузки (или даже полной замены) персонала первых линий
решения типовых проблем пользователя в режиме диалога, полностью в автоматическом режиме
- Прием заявок/жалоб/и тд в голосовой форме
транскрипция (классификации) и последующая передача в вашу тикет систему
- Работа в роли информационного агента
вызовы с напоминанием/подтверждением записи на прием и т. д.
- Работа в роли секретаря
прием, фильтрация, переадресация звонков и т. д.
- Холодные звонки
опросы и тд
Так это еще один ИИ агент на GPT?
Нет. Эта шутка использует другой подход, вместо 'универсальности' как в LLM, здесь применяются легковесный NLP (v1) и модели обученные под конкретно ваши задачи, с логикой на javascript,
что позволяет иметь полностью автономные системы (работающие на вашей стороне) с максимальной производительностью на относительно дешевом оборудовании.
Локальные TTS/STT сервисы обеспечивают сохранность персональных данных и биометрии пользователей.
Например: Core2 Quad с 4G памяти, будет достаточно для ведения от 2-3 одновременных диалогов.
Конечно, если политика безопасности позволяет вам использовать внешние GPT сервисы (типа: ChatGPT/DeepSeek/...) или у вас есть ресурсы для запуска их локально, то, они без проблем могут быть интегрированы в систему.
К сожалению LLM все еще достаточно ресурсоемкое решение и не каждый может себе позволить иметь его в продакшене, так же как и использование публичных GPT сервисов, в таких системах это сопряжено со сл. рисками:
- Утечка корпоративных данных
Изначально LLM модели ничего не знают про специфику вашего бизнеса, по этому, для нормальной работы необходимо дообучить модели на ваших данных (котрые могут содержать конфиденциальную информацию) соответственно все эти данные становятся доступны владельцам сервисов
- Утечка персональных данных пользователей
Когда пользователи взаимодействуют с системой, то все персональные данные которые там появяются так-же становятся доступны владельцам севрвисов
- Утечка биометрии (голосов пользователей)
При использовании внешних Speech-to-Text сервисов, ничего не мешает сохранять и выделять отпечатки голосов из аудио фаргментов (если не используются спец.средства по противодействию этому),
далее это может быть использовано для идентификации пользователей по голосу (без их ведома) или в синтезаторах для создания фейков... - Ресурсоемкость и дороговизна LLM решений (обзорная статья на примере OpenAI)
Как уже было сказано, на данный момент LLM достаточно дорогое и ресурсоемкое решение, даже при низкой цене токена для вас, конечный запрос на железе провайдера стоит разы дороже (и это лишь вопрос времени когда цена токена для вас внезапно поменяется).
Так же важную роль играет отзывчивость системы (зедержка при генерации ответа), на базовых тарифах вы запросто можете получть задержку до 20+ секунд, что вносит дискомфорт в диалоги и раздражение пользователей.
Какие языки поддерживаются?
Для asrd/ttsd список языков достаточно большой, т.к. используются opensouce модели. (см. описание компонентов)
Для NLP есть поддержка: Русский, Англиский (возможно добавление)
Где я могу взглянуть на это?
Пройдя по этой ссылке, онлайн демо с примерами.
Сколько стоит?
Окончательная цена рассчитывается после сбора и обсуждения всех требований.
Свяжитесь со меной и обсудим это.
Компоненты:
- asrd
Высокопроизводительный сервис преобразования речи в текст (pure с)
Возможности: офлайн-распознавание (локальные модели, дообучение), многоязычный, извлечение голосовых характеристик (ivectors).
Языки: английский, немецкий, французский, русский, полный список
API: JSON-RPC, plain HTTP GET/POST - ttsd
Высокопроизводительный сервис преобразования текста в речь (pure с, opensouce версия)
Возможности: автономный синтез (локальные модели, с дообучением), многоязычный, форматы (MP3, WAV, L16).
Языки: английский, немецкий, французский, русский, полный список
API: JSON-RPC, plain HTTP GET/POST - nlpd (v1)
Высокопроизводительный сервис обработки языка (java)
Возможности: работа с небольшими наборами данных, быстрое переобучение, многоязычный режим.
Языки: английский, русский (базовые возможности: имена, числа, телефонные номера, адреса*)
API: WebUI + JSON-RPC - sivr-manager
Веб интерфейс для управления компонентами (java + javascript)
- freeswitch + модули
Класс 5 софтсвитч + sivr модули
Преимущества:
- снижение издержек (на персонале, оборудовании, внешних услугах) [* возможное]
- работа полностью в автономном режиме
- работа на достаточно дешевом оборудовании
- гибкая подстройка под различные задачачи
- многоязычная поддержка
Схема интеграции компонентов